網站靜態化 網頁靜態化 Really Static
一直以來我的網站透過Really Static外掛產生靜態文件,連線網站的時候只有將文件讀取並輸出到瀏覽器,沒有經過CPU運算這樣速度的才會快。
一開始我也透過Cache機制達到加速網站,Hyper Cache + DB Cache Reloaded Fix + Wp Minify,使用這三個外掛,但是只要有透過CPU運算,有很多連線的情況下,就有可能連線錯誤,如果沒記錯的話,我之前自己測試連線到自己網站首頁,按住F5不斷更新網站,一段時間當我放掉之後可能最後畫面會是HTTP ERROR 502錯誤,實際上我這個名不見經傳的網站也不會有很多人來瀏覽,只做這些網站優化也是足夠了。
但是我就是想靜態化網站,不死心一直找,找了很久,後來終於找到可以靜態化網站的外掛Really Static,這是在我網站上面真的可以使用的。
以下介紹使用方式:
1.在網站後台搜尋並安裝Really Static,完成之後啟動到設定頁面。
點選[123-quicksetup] or [quick setup]開始設定
2.然後選擇模式,左邊是測試模式,右邊是LIVE模式,我是直接選LIVE模式,測試模式我還真沒用過。

3.設定網站根目錄,預設值又臭又長,如果第一次嘗試可以先不要修改玩玩看。
設定網站首頁預設值也是很長,如果不修改做測試,完成的時候就要連線到預設的路徑,這裡預設值需要連線到 http://orzalanluo.com/wp-content/plugins/really-static/static/index.html 才會顯示網站首頁,有沒有搞錯這麼長。
我現在的設定是
網站根目錄:/var/www/wordpress/
網站首頁:http://orzalanluo.com/

4.這一步驟是測試你有沒有權限讀寫指定的路徑,成功的話都會是綠色。

5.點擊產生靜態文件
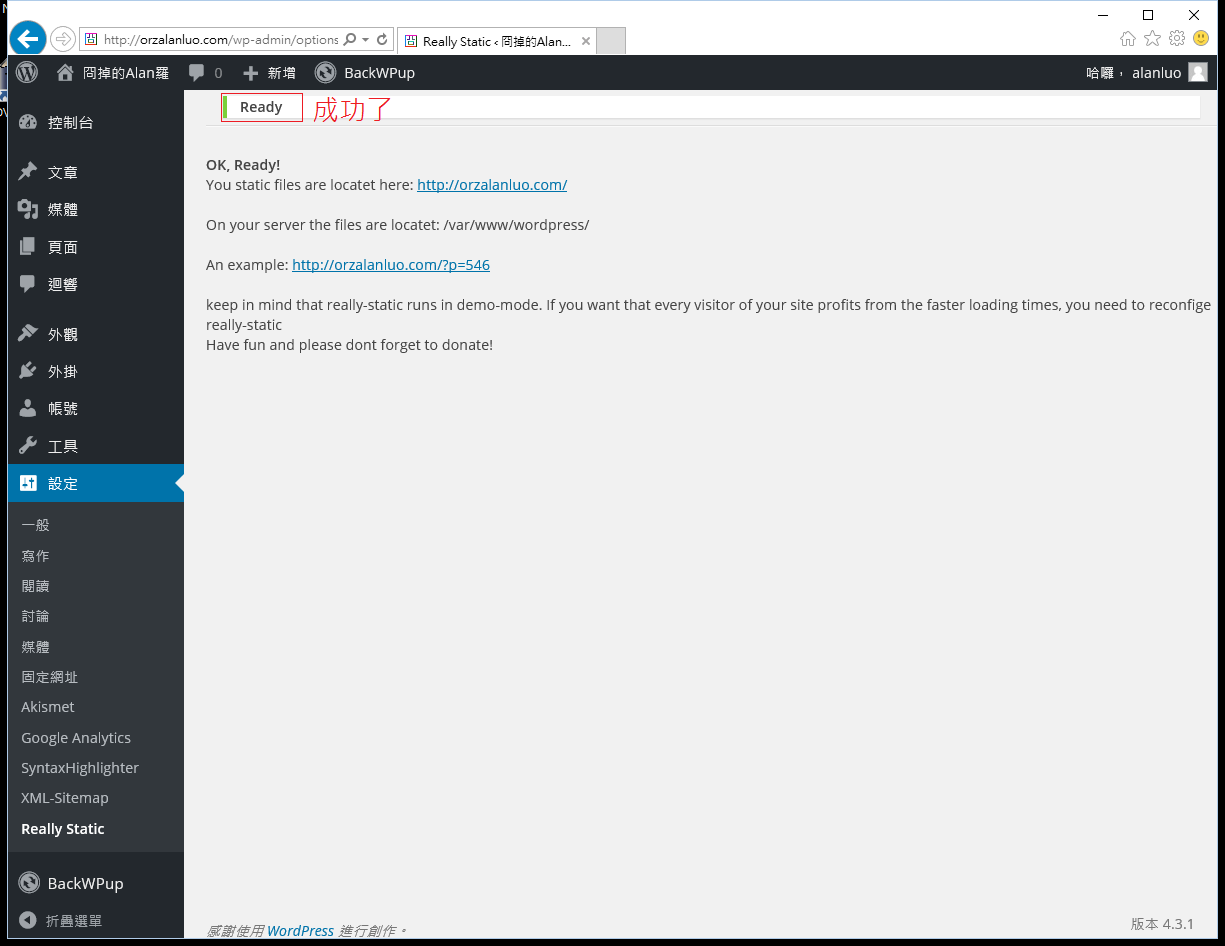
6.成功
7.然後就會在網站根目錄產生很多靜態文件。

8.還沒完喔! 還需要 SSH 登入 VPS,將 web server 設定首頁 index.php 改成 index.html 並重啟 web server,這樣才行。
原本動態網頁連線到 index.php,網頁內容有很多連結,例如: http:// orzalanluo.com/?p=292,實際上是連線到 http:// orzalanluo.com/index.php?p=292,p=292 是參數,就是告訴網站我現在要讀取第292頁的資料,經過PHP程式CPU計算,讀取 Database 資料,最終產生給使用者呈現的畫面。
網站靜態化之後的 index.html 裡面的連結,全部都變成讀取網站資料而已,例如:
http://orzalanluo.com/p=292/index.html 第292頁資料
http://orzalanluo.com/cat=21/index.html 分類 MT4
http://orzalanluo.com/m=201510/index.html 每月彙整 十月 2015
但是還有不完美的地方,我不知道是不是我設定有問題,還是外掛的問題,每當我Po文需要更新資料的時候,繁瑣的步驟常常導致網站出錯。
步驟如下:
1. 網站設定檔改成動態 index.php
2. 重啟 web server
3. 網站後台 [Really static] 設定頁面,[Manual Refresh] 分頁,點擊 [Write all files] 更新文件,漫長等待。
4. 網站設定檔改成靜態 index.html
5. 重啟web server
我已經簡化 1&4 步驟,打指令只是單純的複製檔案。
1. cp index.php_orzalanluo orzalanluo.com
4. cp index.html_orzalanluo orzalanluo.com
如果這些步驟可以省略的話,不知道可以節省多少時間,人生是很短暫的。
然後開始分析怎樣自動完成,步驟如下:
1. 連線到首頁 http://orzalanluo.com/index.php
2. 將內容中的 http:// orzalanluo.com/? 字串全部找出來,取代成之後靜態化的路徑。
3. 將步驟2完成的內容,存成 index.html。
到這裡只完成第一步,上一步驟(2),那些超連結每一個都連線一次,重複步驟(2)(3),一直迭代下去。
例如: http:// orzalanluo.com/?p=292 連結,需要連線到 http:// orzalanluo.com/index.php?p=292,將內容取代成靜態化路徑,內容再存成 /網站根目錄/p=292/index.html。
搞了一整天終於完成,直接看程式,是使用 python 實作,程式碼很簡潔,第一次使用 python 完成稍微複雜的程式。
下載點
重要參數
1. url 請修改成你網站首頁
2. path 請修改成網站根目錄
3. sub_path 測試用,產生靜態文件和連結會加上這個值,可以清空。
4. hdr這個值是上網找的,因為我網站有使用CDN服務(CloudFlare),沒有加上這個值連線會被擋掉。
#!/usr/bin/env python
#version 1.0 by alan
import os
import urllib2
url = 'http://orzalanluo.com/'
sub_path = 'static/'
path = '/var/www/wordpress/'+sub_path
if os.path.exists(path) == False:
os.makedirs(path)
hdr = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Charset': 'ISO-8859-1,utf-8;q=0.7,*;q=0.3',
'Accept-Encoding': 'none',
'Accept-Language': 'en-US,en;q=0.8',
'Connection': 'keep-alive'}
url_list = list()
url_list.append(url+'index.php')
search = url + '?'
search_len=len(search)
for element in url_list:
print element
req = urllib2.Request(element, headers=hdr)
try:
page = urllib2.urlopen(req)
except urllib2.HTTPError, e:
print e.fp.read()
content = page.read()
idx = 0
while True:
idx = content.find(search , idx)
if idx == -1:
break
last = idx + search_len
m1 = content.find('\"' , last)
m2 = content.find('\'' , last)
end = min(m1,m2)
if m1 == -1:
end = m2
elif m2 == -1:
end = m1
url_src = content[idx:end]
param = content[last:end]
idx += search_len
site = search[:-1]+'index.php?'+param
if site.find('#') != -1:
end1 = content.find('#' , last)
param = content[last:end1]
comment = content[end1:end]
content = content.replace(url_src, url+sub_path+param+'/index.html'+comment)
continue
elif site.find('feed') != -1:
content = content.replace(url_src , url+'index.php?'+param)
continue
else:
content = content.replace(url_src , url+sub_path+param+'/index.html')
if site in url_list:
continue
url_list.append(site)
idx = element.find('?')
folder = element[idx+1:]
if idx == -1:
folder = ''
if os.path.exists(path+folder+'/') == False:
os.makedirs(path+folder+'/')
file = open(path+folder+'/index.html' , 'w')
file.write(content)
file.close()
print 'list size='+str(len(url_list))
內容連結也有設定一些例外,連結文字含有 feed 沒有進行靜態化,有可能連結會是 index.php?page=2 沒有在繼續處理靜態化,雖然還可以再加入程式做處理,目前已經夠好了,之後有時間再進行改版。
最後要讓他可以自動執行,設定定時任務,crontab -e ,加入腳本,每10分鐘自動產生靜態文件。
*/10 * * * * /root/web_static.py
腳本也需要執行權限,打指令新增執行權限 chmod +x /root/web_static.py 。
之後只要有修改文章,都不用 SSH 到 VPS 打指令,也不用到 [Really Static] 設定頁面點擊 [Write all files] 產生靜態文件,真是舒服,有Po文或是修改文章,最晚10分鐘之後會更新內容,爽拉! 完全自動化。
2015-11-05
最近發現一個問題,python定時執行腳本有可能沒辦法正常結束,top 裡面會看到很多 cron、python、sh 程式,導致記憶體用盡,FTP 跟 SSH 會因為記憶體用盡沒辦法連線,需要手動 killall python 清理程式。

這樣也不是辦法上網查了一下,可以用 lockfile 方法判斷是是否有正在執行的程式,如果有的話就不要執行,但是我覺得現在情況應該是程式異常時沒辦法正常結束,所以還是要殺掉程式才對,另外寫一個 shell 程式,在執行 web_static.py 之前,先 killall python 殺掉程式,然後將 cron 工作排程改成這個 shell 程式問題就解決了。
#!/bin/bash killall python /root/web_static.py
2015-12-15
突然發現網站右邊的近期迴響網址無法連線,跟之前不一樣的地方多出參數 &cpage=1,可能迴響太多所以網址出現分頁,或是最近升級 WordPress 4.4,我也不知道確切原因,但是程式碼沒有修改的話,就會連結到錯誤網址。
原本網址:
http:// orzalanluo.com/?p=730#comment-86
後來發現:
http:// orzalanluo.com/?p=730&cpage=1#comment-86
如果程式不修改的話,產生的靜態網址連結會是:
http:// orzalanluo.com/p=730/index.html&cpage=1#comment-86
主要修改是要將 &cpage=1 參數忽略掉
新1.1版下載點
以下為主要修改的部分程式碼
if site.find('#') != -1:
end1 = site.find('#')
last = site.find('?') + 1
tag = site.find('#' , end1+1)
if tag != -1:
param = site[last:end1-1]
comment = site[tag:]
else:
param = site[last:end1]
comment = site[end1:]
content = content.replace(url_src, url+sub_path+param+'/index.html'+comment , 1)
continue
elif site.find('feed') != -1:
content = content.replace(url_src , url+'index.php?'+param , 1)
continue
else:
content = content.replace(url_src , url+sub_path+param+'/index.html' , 1)
2015-12-16
新1.2版下載點
進階修改,原本沒有處理 http:// orzalanluo.com/index.php 這些網址,通常是在舊文章、新文章的連結,如果點這些連結會跳到動態網頁,如果之後在點其中的連結,又會跳到靜態網站的首頁,因為動態網頁內的連結都會是有參數 http:// orzalanluo.com/?cat=26 之類的,但是目前網站設定首頁是 index.html,所以實際上是連結到 http:// orzalanluo.com/index.html?cat=26,後面參數 cat=26 直接忽略,靜態網頁帶參數也沒有意義,因為也不會再另外處理。
原本動態網址:
http:// orzalanluo.com/index.php?paged=2
http:// orzalanluo.com/index.php?cat=21&paged=2
http:// orzalanluo.com/index.php?author=1&paged=2
Really Static 靜態化路徑:
http:// orzalanluo.com/page/2/index.html
http:// orzalanluo.com/cat=21/page/2.html
http:// orzalanluo.com/author=1/page/3.html
其中首頁的舊文章超連結是 index.html,但是在分類跟作者裡面的舊文章超連結竟然有差異,如果是第2頁會是2.html、第三頁會是3.html…以此類推,這裡應該也要像首頁舊文章的形式,不知道為什麼會有這樣的差異,目前程式架構還是跟隨 Really Static 的處理方式。
程式原本只有搜尋並取代超連結 [http:// orzalanluo.com/?],現在新增程式處理 [http:// orzalanluo.com/index.php?],又更完美了。
部分程式碼:
search = url + 'index.php?'
search_len = len(search)
idx = 0
while True:
idx = content.find(search , idx)
if idx == -1:
break
last = idx + search_len
m1 = content.find('\"' , last)
m2 = content.find('\'' , last)
end = min(m1,m2)
if m1 == -1:
end = m2
elif m2 == -1:
end = m1
url_src = content[idx:end]
param = content[last:end]
idx += search_len
site = url_src.replace('#038;' , '')
if site.find('paged=') != -1:
m1 = site.find('?')
m2 = site.find('&')
m3 = site.find('paged=')
page_num = site[m3+6:]
if m2 != -1:
param = site[m1+1:m2] + '/page/' + page_num + '.html'
else:
param = 'page/' + page_num + '/index.html'
content = content.replace(url_src , url+sub_path+param , 1)
elif site.find('feed') != -1:
continue
else:
content = content.replace(url_src , url+sub_path+param+'/index.html' , 1)
continue
if site in url_list:
continue
url_list.append(site)